|
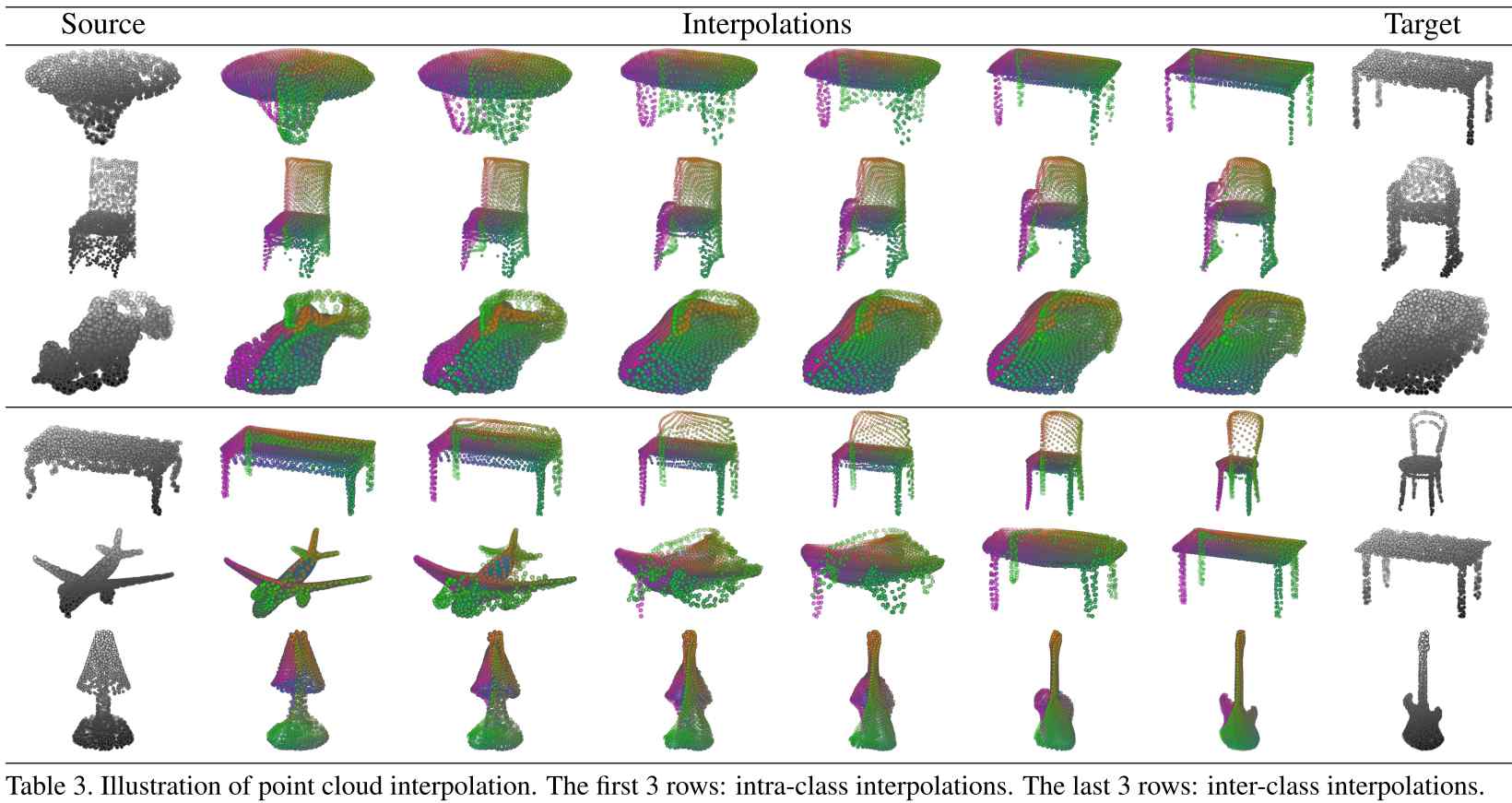
FoldingNet: Point Cloud Auto-encoder via Deep Grid DeformationThe state-of-the-art unsupervised deep auto-encoder of point clouds which reconstruct order point clouds from unordered input, useful for autonomous driving, robotic scene understanding, etc. See our [CVPR'18 spotlight paper (acceptance rate<10%)], [code(in pycaffe)] . |
|

|
Mining Point Cloud Local Structures by Kernel Correlation and Graph PoolingWe propose two new operations, Kernel Correlation and Graph Pooling, to efficiently and robustly improve PointNet, useful for autonomous driving, robotic scene understanding, etc. See our [CVPR'18 paper], [code(in pycaffe)] . |
|
|
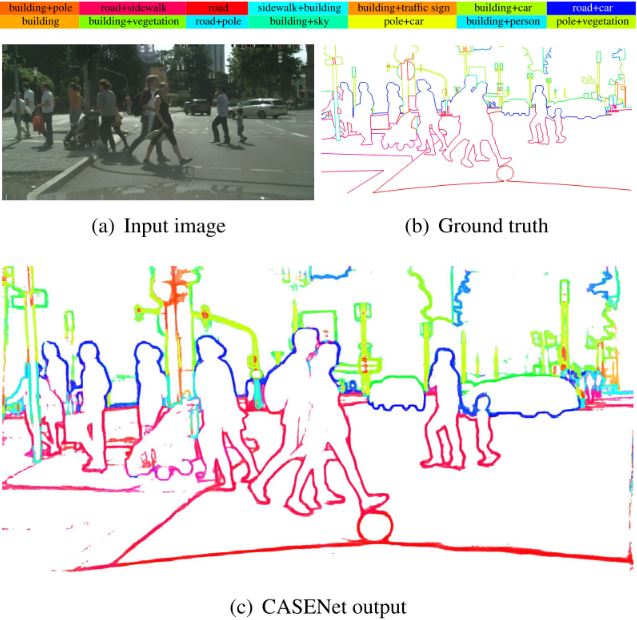
CASENet: Deep Category-Aware Semantic Edge DetectionThe state-of-the-art multi-label semantic boundary detection neural network, useful for autonomous driving, robotic scene understanding, etc. See our [CVPR'17 paper], [code] . |
|

|
Direct Multichannel TrackingA monocular VSLAM algorithm extending LSD-SLAM's input from single-channel gray image to multi-channel feature image. See our [3DV'17 paper] . |
|

|
Deep Active Learning for Civil Infrastructure Defect Detection and ClassificationA deep resisual convolutional neural network trained with our positive-based active learning strategy for multiple types of infrastructure defect detection, including cracks, deposit, and water leakage. See our [IWCCE'17 paper], [slides] . |
|
|
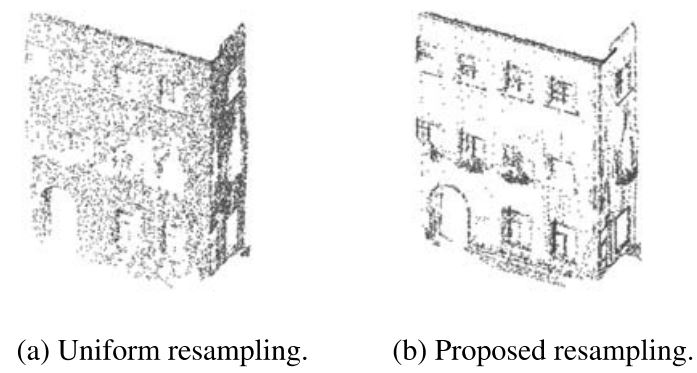
Contour-Enhanced Resampling of 3D Point Clouds Via GraphsAn efficient point cloud resampling strategy using graph signal processing to reduce storage and computation cost for processing and visualizing large-scale 3D point clouds. See our [ICASSP'17 paper] . |
|
|
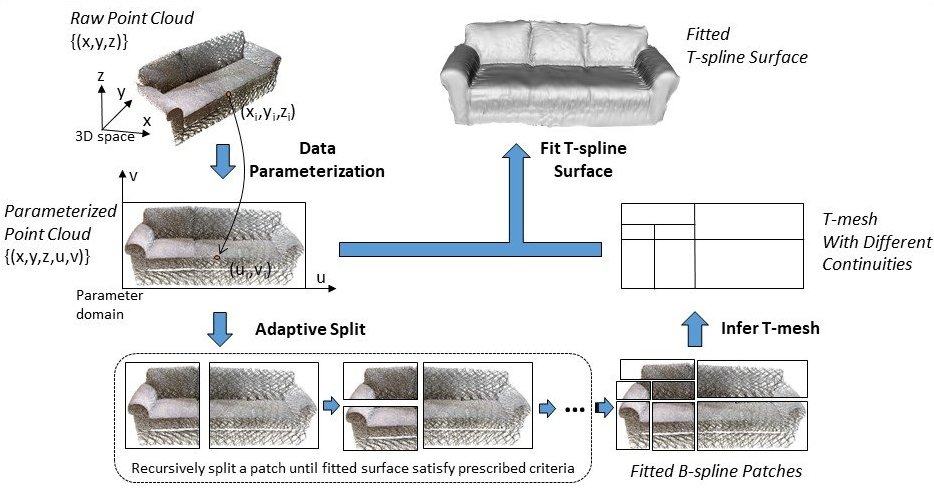
FasTFit: A fast T-spline fitting algorithmThe fastest T-spline fitting algorithm on CPU for organized point clouds, useful for reverse engineering, as-built BIM, point cloud compression, etc. See our [JCAD'17 paper] . |
|
|
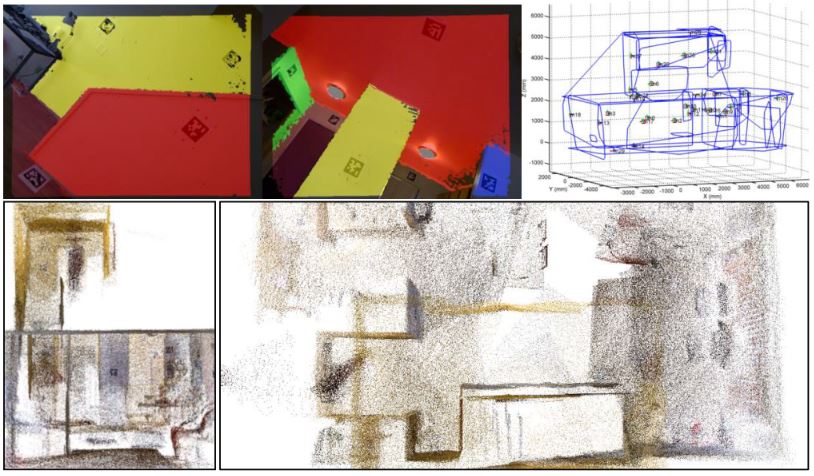
Marker-Assisted Structure from Motion for 3D Environment Modeling and Object Pose EstimationA marker-assisted 3D reconstruction system modeled by camera-marker network, useful for multi-marker based pose estimation for AR/VR/Robotics/Camera Calibration/etc. See our [CRC'16 paper] [code] . |
|

|
Fast Plane Extraction in Organized Point Clouds Using Agglomerative Hierarchical ClusteringThe fastest plane detection algorithm on single-core CPU (>35Hz for VGA size) for organized point clouds. See our [ICRA'14 paper], [slides], [C++ codes] . |
|

|
Vision-Based Articulated Machine Pose Estimation for Excavation Monitoring and GuidanceA prototype excavation monitoring system using markers and cameras for estimating the bucket position. See our [ISARC'15 paper] . |
|

|
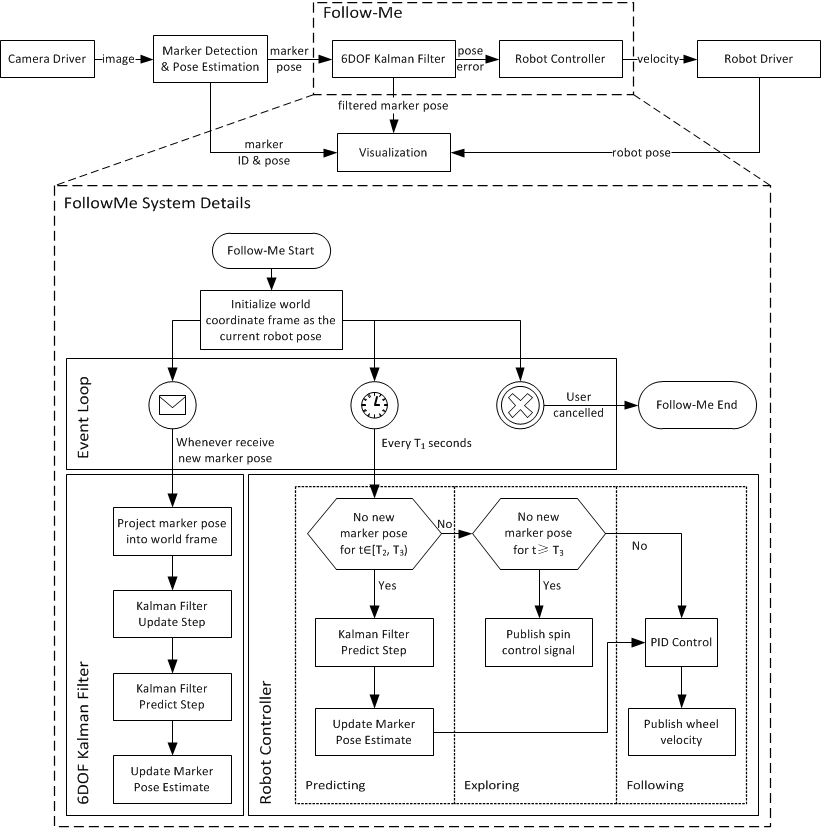
Towards Autonomous Robotic In-Situ Assembly Using Monocular VisionA robotic prototype using AR markers to enable automatic in-situ assembly from an algorithmic architecture design with a single camera. See our [ISARC'14 paper] (Best Paper Award) . |
|
|
Human-Robot Integration For Pose Estimation And Semi-Autonomous NavigationA robotic prototype using AR markers to enable automatic dynamic target following with a single webcam. See our [ISARC'13 paper] . |
|
|
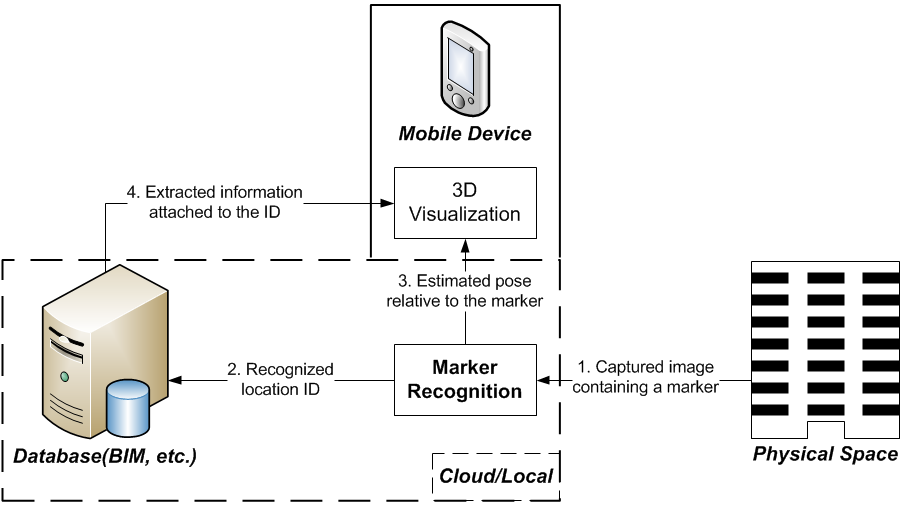
MARvigator: Augmented Reality Markers as Spatial IndicesA new methodology for using Augmented Reality (AR) fiducial markers as spatial indices whose global positions and orientations are known in advance, presenting information in AR at a set of discrete critical spatial locations. See our [CONVR'12 paper] . |
|

|
Point-Plane SLAM for Hand-Held 3D SensorsA robust feature-based RGBD-SLAM algorithm using both points and planes for robust camera pose estimation and 3D environment reconstruction. See our [ICRA'13 paper] . |
|
|
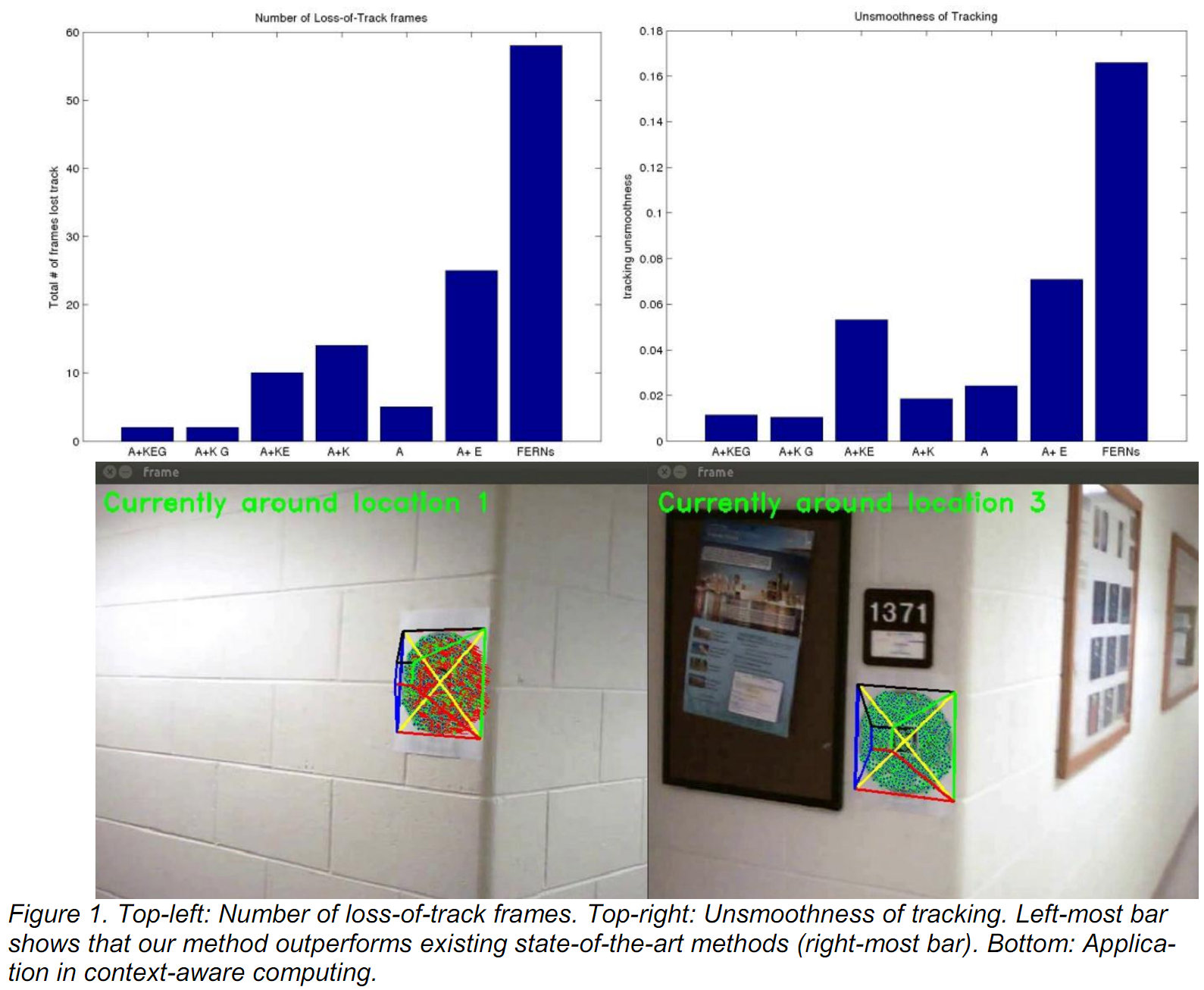
KEG Plane Tracker for AEC Automation ApplicationsA single camera pose estimation algorithm for planar environment, combining two global constraints (geometric and appearance) to prevent tracking errors from propagating between consecutive frames, achieving high accuracy, stability, and robustness. See our [CACAIE'13 paper] . |
|

|
Semi-Auto SVR: Semi-Automatic Single View ReconstructionA semi-automatic reconstruction of buildings into piecewise planar 3D models from a single image with user input of line drawings, using J-linkage-based automatic vanishing point detection. See our [CONVR'10 paper] . |

Assistant Professor, Ph.D.
Department of Civil and Urban EngineeringDepartment of Mechanical and Aerospace Engineering
New York University Tandon School of Engineering
15 MetroTech Center, Brooklyn, NY
E-mail: cfeng[at]nyu[dot]edu
Work: 646-997-3445


